
Quando se usa docker, trabalhar com volumes parece fácil. Basta vincular uma coisa aqui, outra acolá e pronto: seu contêiner já tem acesso à persistência. A coisa muda um pouco de figura quando se trabalha com Kubernetes. Afinal, seus pods podem estar, em qualquer momento, em qualquer um dos nós do seu cluster. E como fica o gerenciamento de disco? E se eu precisar que meus pods tenham identidade? É por isso que hoje vamos entender melhor como gerenciar volumes e artefatos de deploy no Kubernetes.
Pra começar a nossa conversa, o que são esses tais de volumes?
Volumes
Não estamos falando dos decibéis emitidos pela sua aplicação. Se você já trabalhou com docker, deve estar familiarizado com o conceito de volume. Se não, volumes nada mais são do que “pedaços” do seu HD que você diz para o contêiner: “Toma aqui: pode usar como quiser”.
Vez ou outra você vai me ver falando em “disco” ou “HD” ou storage. Todos são termos que, de certa forma, remetem a mesma ideia: um espaço de armazenamento setorizado. O seu disco (mesmo o SSD) está divido em setores minúsculos, onde são armazenados os dados do seu computador. Como uma lista ligada em que um nó aponta para o próximo. E para ler toda a lista, você precisa apenas saber onde ela começa.
Essa definição é relevante porque é assim que os storages são tratados no mundo cloud: blocos de informação. E se você encara seus dados com esse nível de abstração, qualquer coisa que permita leitura-escrita pode ser encarado como um disco. E até mesmo o próprio disco pode ser encarado como um banco de dados.
Toda essa “viagem” apenas para que as nossas aplicações possam guardar estado. E por falar nisso, já ouviu falar em stateless e stateful?
Stateless x stateful
A maior parte das aplicações que desenvolvemos hoje são stateless, ou “sem estado”. Isso quer dizer que essa aplicação não se preocupa em fazer a gestão de como os dados são armazenados, além de não guardar nenhuma informação de quem a invocou na sua memória. Em geral, essas tarefas são delegadas a outro sistema; como a um banco de dados, por exemplo.
Aplicações stateful, por outro lado, guardam estado ou são afetadas pela mudança desse estado. Uma API, por exemplo, que guarda dados da sessão do usuário em memória (ainda que seja uma má prática) é considerada como stateful.
Como você percebeu as aplicações possuem comportamentos e necessidades diferentes. O que exige que o cluster as trate de forma distinta também. É aí que entram o deployment e o statefulSet
Deployment vs StatefulSet
Você já deve ter visto um Deployment de perto em algum lugar. Basicamente, deployment é um artefato que diz ao Kubernetes, o quê, onde e como deve ser publicado.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80O exemplo acima diz ao Kubernetes que você precisa ter uma instância do nginx rodando em algum lugar, expondo a porta 80. Muito mais informações podem ser definidas no deployment – como probes, limites dos recursos de cada pod, afinidade com pods e assim por diante. Uma característica importante do deployment é que a identidade do pod e onde ele está não é importante. Assim descartá-lo e construir um novo “onde der” é o comportamento padrão do Kubernetes.
Agora vamos conhecer o statefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: nginx-statefulset
labels:
app: nginx
spec:
serviceName: nginx
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:stable
ports:
- containerPort: 80
volumeMounts:
- name: www
mountPath: /usr/share/nginx/html
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 1GiO statefulSet é muito parecido com o deployment, como você pode ver. A grande diferença é que o statefulSet garante duas coisas: O nome dos pods jamais irá mudar. E cada pod terá sempre um volume próprio e não-compartilhado. Essas duas propriedades são interessantes para cenários em que precisamos ter previsibilidade no nome – mantendo um DNS específico e imutável para um pod – e que as diversas réplica não irão compartilhar o mesmo volume.
Resumindo: Se você está querendo entregar aplicações stateless – como APIs, por exemplo – e pode usar um ingress ou um loadbalance para acessar as diversas instâncias, utilize um deployment. Quando você for entregar uma aplicação que gerencia o acesso aos dados, que cada instância mantém estados diferentes, não acessando o mesmo volume e precisam ser acessadas distintamente, vá de statefulSet.
Até aqui nós já entendemos os conceitos de stateless e stateful, de deployment e statefulSet e também de volumes. Mas como essas coisas funcionam no Kubernetes?
Como o Kubernetes gerencia volumes?
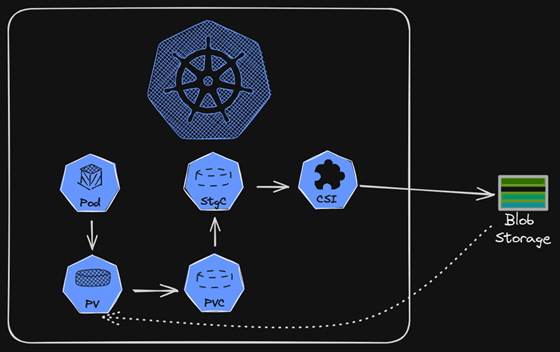
O esquema acima nos mostra a cadeia de dependências entre os diversos artefatos que garantem acesso aos dados. O pod se conecta a um Persistence Volume (PV), que foi criado através de uma Persistence Volume Claim (PVC) baseada nas restrições especificadas por uma Storage Class (StgC) que se comunica com o blob através de uma implementação do driver CSI (Container Storage Interface). Mas o que é cada uma dessas coisas?
PV e PVC
Entenda o PVC como a solicitação de um pedaço do disco que está disponível. Nele você consegue definir modos de disponibilidade do recurso. Por exemplo, você pode dizer que apenas um pod é capaz de operar esse volume (RWO), ou que vários pods podem ler e escrever (RWX). Além disso, você pode definir nome, tamanho, construir os dados baseando em outro disco, a storage class pra quem você está solicitando o disco.
Ou seja, com o PVC estamos tentando provisionar um PV. E sim, você pode criar PV manualmente. Mas sinceramente, não há razão para isso.
Veja um exemplo de manifesto que cria um PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-longhorn
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 20GiE aqui um deployment de um nginx utilizando o PVC recém-criado.
apiVersion: v1
kind: Pod
metadata:
name: pod-com-volume
spec:
containers:
- name: app
image: nginx:stable
volumeMounts:
- name: dados
mountPath: /usr/share/nginx/html
volumes:
- name: dados
persistentVolumeClaim:
claimName: pvc-longhornStorage Class e CSI
Imagine comigo: Se o Kubernetes fosse o responsável direto por fazer a gestão de acesso aos storages, ele teria que construir diversas implementações, certo? Afinal tem os discos SSD, NVMe, Azure Blob Storage, Amazon S3, Pendrive, MicroSD… Então o que ele faz? A boa e velha inversão de dependência! Uma definição/interface padrão foi criada para que os vendors tornem as suas soluções compatíveis com o Kubernetes. Isso é o CSI: Container Storage Interface.
Cada CSI vai prover funcionalidades diferentes. Alguns drivers podem não suportar RWX ou replicação, por exemplo, enquanto com outros drivers isso é possível. Também pode ser que você queira segmentar os discos, vinculando a determinadas tags de seleção. A definição de quais features serão utilizadas para um volume está atrelada ao Storage Class.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: longhorn
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: Delete
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "3"
staleReplicaTimeout: "30"
fsType: ext4Observe que em provisioner nós especificamos que essa storageClass utiliza o driver CSI do Longhorn. E também outros parâmetros que definem até mesmo o sistema de arquivos que utilizado nos volumes criados à partir dessa storage class.
Para o Longhorn, no objeto parameters, você pode definir, por exemplo, seletores, indicando em qual disco os volumes serão criados. Veja o exemplo à seguir:
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-fast
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: "Delete"
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "1"
staleReplicaTimeout: "30"
fsType: "ext4"
diskSelector: "ssd"
nodeSelector: "ssd"As PVC que utilizarem o storageClass longhorn-fast apenas serão agendados nas máquinas com a tag “ssd” e nos discos com a tag “ssd”.
Esse manifesto já é um spoiler do que vem à seguir, quando instalarmos o Longhorn no nosso cluster. Te vejo lá!