
Como eu disse no primeiro artigo desta série, é totalmente possível você configurar o k3s no seu computador pessoal. Mas a nossa aventura é um pouco mais desafiadora! Chegou a hora de transformarmos os nossos Raspiberry Pi em agentes kubernetes. O verdadeiro agente 003.14!
O que é um raspiberry pi?
Pode ser que a essa altura do campeonato você ainda não saiba o que é um Raspiberry Pi. E está tudo certo! Até pouco tempo eu também não conhecia. E quando conheci, pensei que era coisa de outro mundo operar um desses. Mas não é! Acredite em mim. É tão fácil como operar qualquer computador.
Isso porque, de fato, o Raspiberry PI é uma placa desenhada para operar um como um computador simples. As configurações são ligeiramente modestas e não há como você melhorar coisas como processador e quantidade de memória, como fazemos nos nosso computadores pessoais. Mas há sim como expandir suas funcionalidades, adicionando novos periféricos (como câmeras, sensores e atuadores em geral).

Pense nele como um “Arduíno com esteroides” (sim, ele é fake natty). Ele possui muito mais memória e poder de processamento. Na verdade, ele é capaz até de rodar um sistema operacional – finalidade para a qual o Arduino não foi projeto. Desta forma, você pode utilizá-lo como uma versão reduzida de computador pessoal (isso não inclui games AAA). Há também quem o utilize como home-server, central multimídia, qualquer coisa que você faria com um computador dedicado, mas que não está disposto a pagar uma média de 2000 dinheiros.
Aliás, a razão inicial do “Projeto Raspiberry” foi justamente popularizar o acesso aos computadores, através de um dispositivo replicável (sim, ele é open-source), de baixo consumo energético (5v, 3A e um sonho são suficientes) e barato. No entanto, para nós brasileiros, ele está custando quase o mesmo que um notebook positivo (O Raspiberry 5 está custando, hoje, cerca de 800 reais). O que fez com que outras versões acabassem se despontando no mercado como alternativas mais baratas. É o caso do Orange Pi. Com os mesmos recursos consegue custar, em média, incríveis 200 reais + impostos (Soyuz nerushimyy respublik svobodnykh).
No nosso experimento, conto com três Raspiberry Pi 4B. Na imagem abaixo vocês vão encontrar a especificação do Raspi, mas eu quero chamar a atenção ao storage deles: É um pendrive SanDisk! Eu tentei colocar um disco SSD como storage principal. Contudo, o SSD – tanto o uso quanto o acesso – pode consumir muito da pouca energia que o “Raspi” tem à disposição. O que me obrigaria utilizar uma fonte de alimentação que provê energia além da especificação. E você sabe em que isso pode resultar: de encurtamento da vida útil dos componentes até queima da placa.
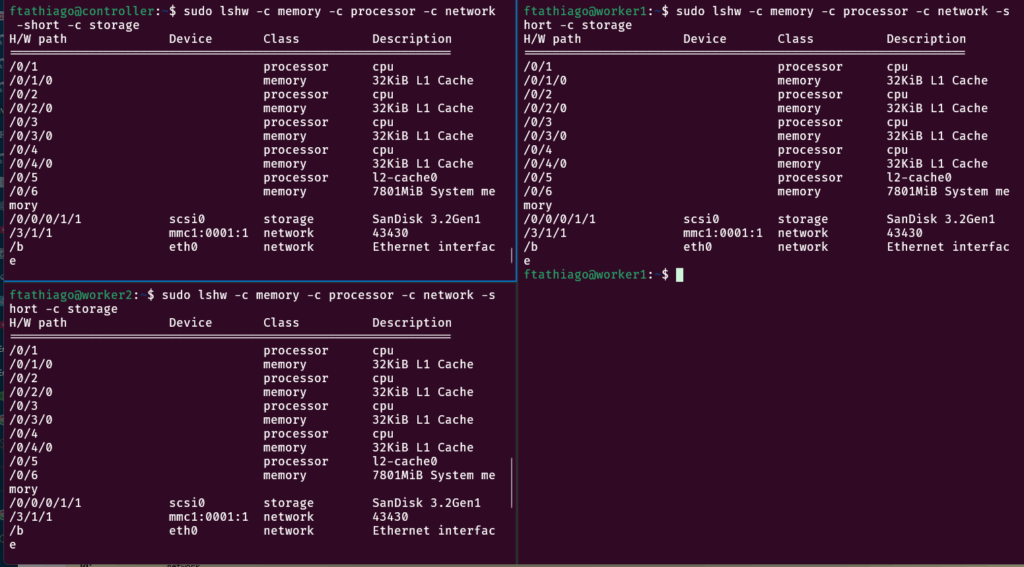
Especificação técnica:
- Processador: Broadcom BCM2711, Quad-core Cortex-A72 (ARM v8) 64-bit @ 1.5GHz.
- Memória RAM: Disponível em versões de 1GB, 2GB, 4GB e 8GB (LPDDR4).
- Saída de Vídeo: 2 portas micro-HDMI, com suporte para 4K@60fps (ou dois monitores 4K@30fps).
- Rede: Wi-Fi 802.11ac (2.4 GHz e 5.0 GHz), Bluetooth 5.0, Gigabit Ethernet.
- Portas USB: 2 portas USB 3.0 (super rápidas) e 2 portas USB 2.0.
- Alimentação: Conector USB-C (requer fonte 5V/3A).
- Armazenamento: Slot para cartão microSD.
- Conectividade: GPIO de 40 pinos (compatível com acessórios anteriores), interface CSI para câmera, interface DSI para display, áudio/vídeo composto.
- Dimensões: Aprox. 85.6mm x 56.5mm x 17mm.
Instalando os agentes
Recapitulando:
A topologia da rede foi apresentada no primeiro artigo. Dê uma olhada lá caso você tenha esquecido. O inventário do ansible também foi apresentado no segundo artigo. Então, sempre que você vir o parâmetro -i [diretório | arquivo] em uma linha de comando, estou apontando para aquele inventário.
Antes de instalar os agentes, recomendo que você rode as atualizações do ubuntu em cada um deles. Você pode fazer isso via ansible, se quiser. Eu particularmente prefiro fazer, ao menos essa etapa, manualmente. Assim eu consigo acompanhar o processo visualmente em cada um dos computadores.
Recuperando Token do controller
Você tá achando que é festa assim? Só sair especificando um IP e tá tudo certo? NÃO! Todo agente de kubernetes precisa de uma chave única de autenticação para construir o relacionamento. Sem esse token, quando você executar kubectl get nodes os seus nodes jamais irão aparecer conectados ou prontos para comunicação.
Recuperar esse token é fácil. Dentro da máquina controller, digite o comando:
sudo cat /var/lib/rancher/k3s/server/node-tokenE agora você pode alterar uma variável no inventário, adicionando esse valor:
all:
vars:
K3S_TOKEN: 'achou mesmo que eu iria colocar o token aqui?'
cluster_token: ""Considerações a respeito do token
Você, mais do que ninguém, sabe o que irá executar nesse ambiente e o quão exposto para a internet pública ele está. Dito isso, é uma decisão sua registrar esse valor em plain text no seu repositório e versionar isso. Ou, assim como eu fiz, deixar isso nas variáveis de ambiente e capturar esse valor por lá.
Outra opção seria você instalar controller e agentes no mesmo playbook. Não é uma abordagem que eu gosto, mas tornaria possível configurar os agentes sem ter que tocar no token.
- name: Instala o controller
hosts: controller
become: yes
gather_facts: no
tasks:
- name: Instala o k3s como controller
shell: curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION=v1.27.2+k3s1 sh -s - --write-kubeconfig-mode 644 --bind-address 192.168.1.212
register: k3s_script_controller
- debug: var=k3s_script_controller.stdout_lines
- name: Mostra o token
shell: cat /var/lib/rancher/k3s/server/token
register: show_token_output
- name: Propaga token para os workers
run_once: true
add_host:
name: k3s_token_holder
groups: token_holder
K3S_TOKEN: "{{ show_token_output.stdout }}"
- name: Instalar o agente
hosts: workers
gather_facts: yes
tasks:
- name: Instala o k3s como agent
shell: curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION=v1.26.9+k3s1 K3S_URL=https://192.168.1.212:6443 K3S_TOKEN="{{ hostvars['k3s_token_holder'].K3S_TOKEN }}" sh -
register: agent_output
- debug: var=agent_output.stdout
O segredo para usar a mesma variável em playbooks diferentes está na task Propaga token para os workers. Essa task cria um host virtual, onde armazena o token como variável de ambiente. Esse host virtual é acessado por cada node e busca lá a informação do token.
Essas instalações não costumam demorar. Caso esteja levando mais de dois minutos, aborte o processo e tente manualmente. Pode ser que o seu terminal esteja esperando alguma interação que nunca irá acontecer via Ansible.
Instalando manualmente o k3s como agente
A linha abaixo instala o k3s no modo agente no computador:
curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION=v1.26.9+k3s1 K3S_URL=https://192.168.1.212:6443 K3S_TOKEN="{{ hostvars['k3s_token_holder'].K3S_TOKEN }}" sh -Repare em algumas propriedades
- K3S_URL: Aqui você precisa especificar o endereço do seu controller. Pode usar o DNS name, caso tenha um DNS interno, ou o IP. Eu prefiro IP por conta da resolução mais rápida. A porta 6443 é a porta onde está exposta a API do k3s. Não altere esse valor.
- INSTALL_K3S_VERSION: A versão do k3s que está sendo instalada. Instale a mesma nos controller e workers.
- K3S_TOKEN: O token que conseguimos na etapa anterior.
Validando a instalação do agente
Aguarde alguns minutos (vá tomar uma água e endireitar a coluna). E digite no seu terminar (pode ser o da sua máquina ou no terminal do controller):
kubectl get nodesVocê deverá ver uma lista com todos os nodes vinculados ao controller:

Na imagem acima, temos os workers e os controllers. E já temos algumas roles atribuídas. Se você executar o mesmo comando, talvez a coluna ROLES esteja quase vazia. Isso porque as roles e labels precisam ser especificadas por você.
Roles, Labels, Affinity
Em um cluster real, você teria um (ou dois) node exclusivo para rodar como controlador e todos os demais poderiam atuar como workers. Porque isso?
O control-plane precisa cuidar e coordenar tudo o que está acontecendo no seu cluster. Só isso já é muita tarefa pra ele executar. Se uma carga de trabalho esgotar os recursos da máquina onde o control-plane está hospedado, todo o cluster será afetado. O mesmo pode ser dito em um momento de restart do cluster. Se os serviços do k3s competirem por recursos dos seus workers, você pode criar instabilidade ou o seu cluster, após uma queda, levar um bom tempo até estar disponível novamente.
Por isso, para cada node é possível aplicar Roles e Labels que ajudam a catalogar e a definir onde o seu container irá se hospedar, através de affinity ou taint. Roles são mais retritas, e geralmente utilizadas para atribuir “papéis” aos computadores no seu node pool. O k3s, por exemplo, utiliza roles para saber onde subir o control-plane. Já as labels são um par chave-valor que tornam capaz atribuir características aos nodes – e qualquer outro artefato no k3s.
No nosso caso, utilizamos uma label específica de arquitetura do node para definir onde subiremos os nossos containeres. Abaixo um exemplo de deployment com este node affinity definido:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/arch
operator: In
values:
- arm64
- key: node-type
operator: In
values:
- workerDefinindo roles e labels
Esse comando você pode optar por rodá-lo como shell no controller à partir do ansible. Mas eu prefiro rodar esse na mão mesmo.
kubectl label nodes controller kubernetes.io/role=worker
kubectl label nodes worker1 kubernetes.io/role=worker
kubectl label nodes worker2 kubernetes.io/role=worker
kubectl label nodes controller node-type=worker
kubectl label nodes worker1 node-type=worker
kubectl label nodes worker2 node-type=workerO seu kubectl get -A all deve star muito parecido com o meu.
Agora que temos nodes configurados, onde vamos persistir os dados?
No próximo post vamos mergulhar um pouco na teoria do kubernetes para entendermos melhor como são trabalhados os volumes e depois instalaremos o Longhorn para gerenciar nossos storages.