
No que diz respeito a conceitos, todos os message brokers são muito parecidos. O algoritmo do Kafka, no entanto, apresenta algumas novidades que permitiram ele chegar ao patamar de 1.1 trilhões de mensagens processadas por dia! Para extrair todo esse potencial, é preciso que a pessoa desenvolvedora saiba como o Kafka funciona, facilitando o processo de tomada de decisão – no desenvolvimento ou na arquitetura.
Para encontrar uma documentação detalhada sobre o Kafka, você pode navegar até o site da Confluent e ler a documentação disponível, ou ainda ir direto à fonte, na página da documentação do Apache Kafka.
A melhor forma de entender o funcionamento do Kafka é entender o fluxo da mensagem.
Entendendo fluxo das mensagens
Antes, é preciso que eu destaque o fato de que, quando falamos de Kafka, tudo é tópico. Ele não entende o conceito de filas – apesar de você conseguir utilizar um tópico dessa mesma maneira. E quando falamos de mensagem, nos referimos ao dado armazenado no tópico e não especificamente ao conceito de mensagem x evento. Assim como o caso de filas, mensagem e evento tem o mesmo significado dentro da terminologia do Kafka. Agora que alinhamos nosso vocabulário, vamos seguir em frente. Para saber mais sobre filas e mensageria, veja o artigo anterior dessa série.
Produzindo mensagens
Toda mensagem é produzida por um software que, nesse relacionamento é chamado de producer. Isso não quer dizer que você precisa de um programa específico para isso. O seu backend de vendas pode, além de confirmar no banco de dados as informações, produzir a mensagem no tópico do Kafka. O único trabalho do producer é construir a mensagem e enviá-la ao Kafka, especificando o tópico de destino.

Qual é o formato de uma mensagem?
No Kafka a mensagem possui um formato específico que auxilia no seu processo de armazenamento e leitura. Eu diria que também no processo de pesquisa, já que o Kafka permite execução de pesquisa nos tópicos. A mensagem possui um offset, key, message, headers, timestamp.
Offset
As mensagens ficam armazenadas fisicamente no Kafka. E para que ele possa se “lembrar” da ordem em que elas chegaram, é preciso anotar essa informação em algum lugar. Esse é o offset. Evidentemente, o valor do offset não é definido por você, mas pelo Kafka quando a mensagem chega até o tópico.
O fato de saber a ordem das mensagens, abre uma série de possibilidades. Por exemplo: o consumidor pode solicitar ao Kafka as mensagens desde o offset x, executando assim um replay do consumo das mensagens. Você vai precisar de um replay quando perder dados ou necessitar entender o comportamento da aplicação diante de uma série de eventos.
O offset também permite ao Kafka saber quais mensagens já foram consumidas. Nesse caso, offset acaba funcionando como a informação posicional de um ponteiro. Ou seja, quando o consumidor solicita a próxima mensagem, o Kafka observa onde está o seu ponteiro e envia a mensagem com o offset “ponteiro + 1” ao consumer.
Key
O conceito de chave no Kafka não é diretamente ligado ao conceito de chave primária, como vemos em banco de dados. Você deve olhar para as chaves, no Kafka, quando a ordem de execução das mensagens é importante.
Por exemplo: suponha que você tenha o campo nome. Inicialmente seu valor era “João”. Mas em algum momento o valor foi alterado para “José” e por fim, foi alterado para “Jonatas”, sendo “Jonatas” o nome correto. O que aconteceria se a alteração de “Jonatas” acontecesse antes da alteração para “José”? Qual seria o valor do campo nome?
Como o Kafka pode trabalhar com partições (veremos mais tarde o que são) e também ser “clusterizado”, sem o uso da Key, a ordem das mensagens não pode ser garantida incorrendo no erro do nosso exemplo. Com o uso da Key, aí sim o Kafka consegue garantir o resultado final esperado: as alterações acontecerão na ordem em que foram recebidas.
Message, Headers e timestamp
Message é o valor de fato da mensagem que você deseja armazenar no Kafka. Geralmente armazena-se no formato JSON, mas você também pode utilizar base64. O Kafka pode armazenar mensagens de qualquer tamanho, mas quanto maior a mensagem, mais lento é o seu processamento. Por isso ele já vem configurado para armazenar, no máximo, 2mb de mensagem. Se você tiver mensagens maiores que isso, você está fazendo errado.
Headers são informações referentes a mensagem, mas que não compõe o seu payload. As informações presentes no header vão depender da arquitetura adotada. Os dados que são mais comuns são a origem da mensagem (o sistema que a gerou, no caso) e o CorrelationId para permitir a rastreabilidade da mensagem.
E timestamp são as informações de data e hora da recepção da mensagem pelo Kafka, diferindo em alguns milissegundos da data-hora da mensagem gerada. Se você desejar mapear todo o fluxo da mensagem em um stream, convém adicionar ao header o timestamp da geração da mensagem.
Como a mensagem é armazenada?
Dentro do Kafka podem existir vários tópicos: o tópico de venda confirmada, o tópico de transação autorizada e assim por diante. Durante o envio da mensagem, o producer especifica qual é o tópico de destino, onde a mensagem será armazenada e disponibilizada aos consumers. E é aqui que precisamos aprender mais um conceito do Kafka: partições. Cada tópico pode ter uma ou mais partições. A principal função das partições e dividir a carga do trânsito de mensagens, permitindo que mais de uma aplicação consuma os dados da mesma fila. Assim, se você tem um tópico com quinhentas mensagens e duas partições, cada tópico terá aproximadamente duzentas e cinquenta mensagens. E eu digo “aproximadamente”, porque o Kafka utiliza algoritmos para distribuir as mensagens entre as partições. Logo, pode ser que em uma eu tenho duzentas mensagens e na outra partição eu tenho trezentas.
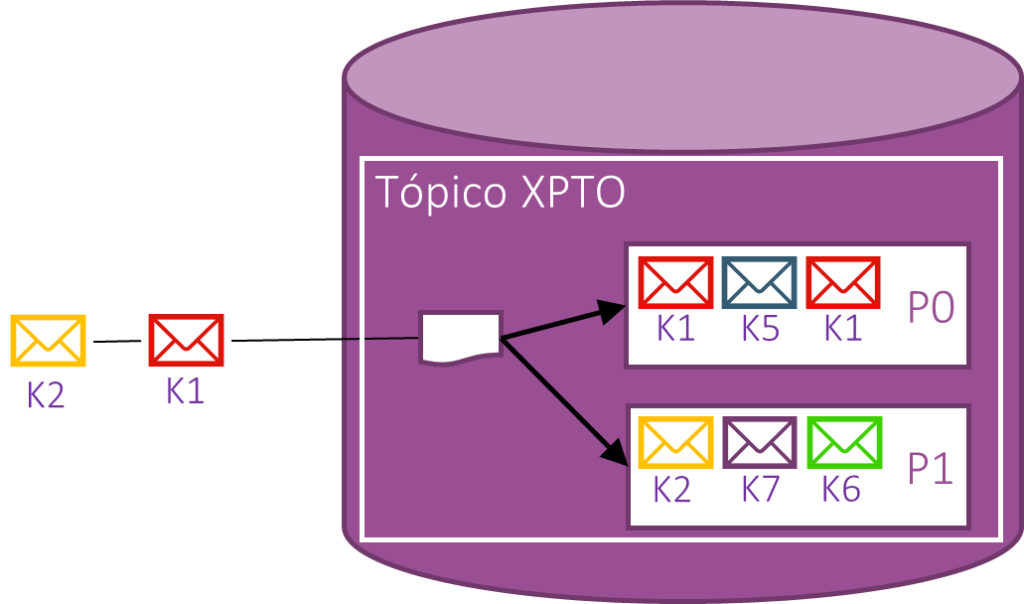
A imagem acima é um exemplo de como as mensagens são armazenadas no Kafka. Considere que as indicações “Kx”, embaixo de cada mensagem é referente a sua chave. Olhando a partição zero (P0), vemos que ela contém mensagens com a chave K1. Ainda na mesma imagem, observa-se que está chegando uma nova mensagem com a chave K1. Neste caso ela será obrigatoriamente encaminhada para a PO. Por sua vez, a nova mensagem K2 será encaminhada para a partição P1, porque está já contém uma mensagem com a chave K2.
Consumindo mensagens
Consumidores ou consumers são as aplicações que fazem uso das mensagens armazenadas no tópico. Quando um consumer começa a rodar, ele fará operações pull em um determinado tópico no Kafka, solicitando novas mensagens. Também é tarefa do consumer confirmar ao Kafka o recebimento da mensagem, que pode ser feito de duas maneiras: commit automático ou commit manual.
Commit automático x Commit manual
O commit automático é o comportamento padrão. Após um determinado tempo (cinco segundos é o padrão, mas pode ser alterado) o Kafka vai entender que a mensagem foi recebida corretamente. Neste caso, ele irá atualizar o seu ponteiro com o offset da mensagem enviada.
Já o commit manual, como é de se imaginar, precisa que a aplicação informe ao Kafka que a mensagem foi recebida. Neste caso, é preciso configurar outros parâmetros de timeout para que o broker não segure eternamente a mensagem caso o consumer tenha colapsado, liberando então o consumo para outra instância da aplicação.
O perigo do commit automático é que, caso algum erro fatal leve a aplicação consumidora a terminar inesperadamente, a próxima instância do consumer não terá chance de reprocessar a mensagem cujo processamento falhou. Para isso, teria de ser criado um mecanismo que permitisse a aplicação retornar ao offset com falha. O que nem sempre é possível.
Exatamente por isso, embora não livre de falhas, a opção por commits manuais é a mais utilizada. Neste caso, a operação de commit da mensagem só é efetuada quando todo o processamento é encerrado. Como são operações rápidas, é muito difícil que a aplicação “morra” entre o fim do processamento e a chamada do commit no Kafka. Porém, se este pode ser um problema para você, convém pensar em formas auxiliares para garantir a idempotência no consumo das mensagens.
A relação entre consumers e partitions
Nós já vimos o que são partitions e como elas funcionam. Mas ainda não explicamos como ela consegue permitir o aumento da vazão de mensagens. A questão é que o aumento não está diretamente ligado às partições, mas na possibilidade de termos mais de uma aplicação consumindo os dados no tópico. Por considerarmos que eventualmente a ordem pode ser importante, não seria aceitável que duas instâncias de uma mesma aplicação consumissem os dados de uma mesma partition. Isso tornaria o controle do offset caótico e sujeito a falhas e desordenamento no consumo das mensagens. Então a primeira coisa que você precisa saber dessa relação é que uma partição pode servir a apenas uma aplicação consumidora. Por outro lado, um consumer pode consumir mensagens de várias partições. Isto nos leva ao seguinte esquema:
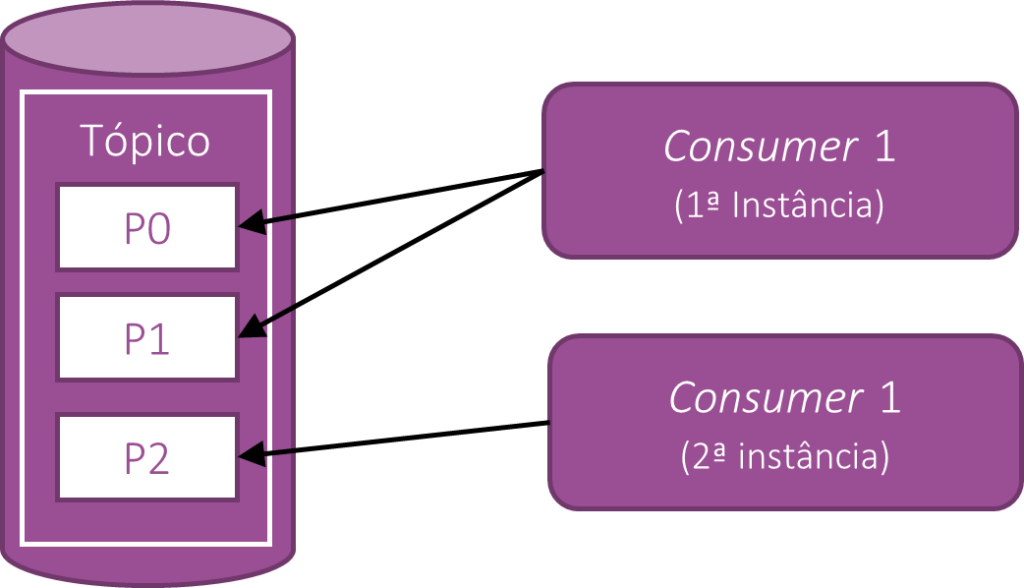
Na imagem acima podemos ver um tópico, com três partições, e duas instâncias da mesma aplicação consumidora. Neste caso, a primeira instância observa as partições P0 e P1 enquanto a segunda instância observa apenas a partição P2. Caso uma terceira instância do Consumer1 seja levantada, teremos então cada consumidor observando apenas uma partição. E por fim, caso uma quarta instância de Consumer1 seja levantada, ela não se conectará a nenhum outro consumer. Ficará em espera até que um dos consumidores já conectados fiquem off-line para o Kafka.
Como duas aplicações podem consumir a mesma partition: Consumer Group
Retomando o nosso exemplo de vendas, quando a transação do cartão é confirmada, as aplicações de Logística, Notificação e Faturamento precisam ser notificadas para fazer os seus devidos processamentos. Esse seria o caso em que aplicações de naturezas diferentes precisam consumir a mesma mensagem. Mas como vimos, o Kafka permite que apenas uma instância conectada por tópico. Como quebrar essa regra? Utilizando Consumer Group!
O consumer group nada mais é do que uma string única que é compartilhada entre aplicações de mesma natureza, e é informada na conexão da aplicação consumidora com o Kafka. Comumente utilizamos o nome da aplicação, concatenado com outras informações que tornem a string única para o seu contexto (o nome DNS ou “domínio + nome da aplicação” são bons exemplos). Para simplificar, neste exemplo utilizarei as letras L, N e F para as aplicações de Logística, Notificação e Faturamento respectivamente:
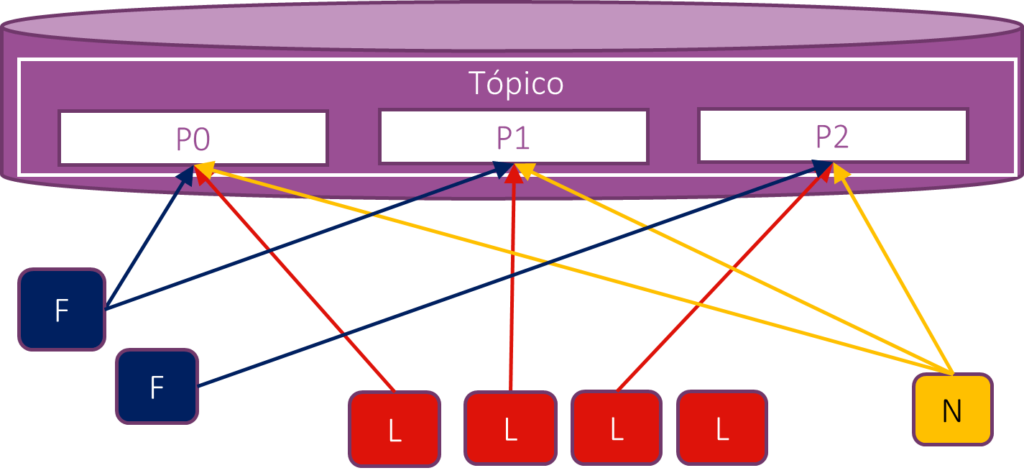
Concordo que à primeira vista pode parecer confuso, mas o que realmente deve chamar a atenção é que para cada partição há mais de um consumer conectado. O que os difere é simplesmente o grupo de consumidores a que pertencem. Repare ainda que a quarta instância de “L” não está conectada a nenhuma partição, já que seus pares no consumer group estão todos já vinculados a uma das três partições disponíveis. Esse comportamento só é possível porque especificamos consumer groups distintos para cada grupo de aplicações.
Concluindo
Nesse extenso artigo nós aprendemos vários conceitos envolvendo o Kafka. Alguns ficaram de fora – como a clusterização e outras otimizações – por conta apenas do escopo desse artigo. Todavia, o que vimos até então já é o suficiente para que possamos escrever as nossas primeiras aplicações utilizando Kafka de forma segura. Alguns detalhes de configuração, que ficaram de fora nesse artigo, serão abordados futuramente, quando estivermos com a mão na massa.
Muito obrigado por nos acompanhar até aqui e até o próximo artigo!
Massa!
Muito bom o artigo, parabéns!
Excelente artigo!
Obrigado por compartilhar esse conhecimento.
Abraços…
Muito obrigado pelo feedback, Valdir! Qualquer coisa, só entrar em contato 🙂