Quem trabalha com sistemas cloud native, com certeza já desejou ter acesso irrestrito ao Kubernetes, sem as travas que os times de plataforma/devops costumam impor a nós, meros mortais. Eu, que estou longe de morar no Olimpo, dei os meus pulos para ter o k8s em casa. E quer saber? É muito divertido! Se você quer ir além de apenas “simular” o k8s no seu computador, nessa série eu vou te pegar pela mão e te mostrar o passo-à-passo de como estou criando um cluber kubernetes com raspiberry pi e um kit xeon.
Antes, um agradecimento
Com certeza eu não tirei todo esse conhecimento da minha cabeça. Eu não sou SRE e nem atuo com times de infraestrutura. Muito do que eu consegui fazer foi lendo documentação e alguns blogs com os caminhos das pedras. O que me inspirou a escrever essa série (já que a maior parte do material está em inglês).
Assim, preciso agradecer ao time do k3s, que além de terem feito uma ferramenta sensacional, também construíram uma documentação extremamente rica. Você pode acessar o conteúdo aqui: https://docs.k3s.io/
E também ao pessoal do https://rpi4cluster.com/, um site que contém um passo-à-passo detalhado sobre como fazer um cluster com raspiberry pi.
Valeu, galera!
Por que o Kit XEON?
Aqui eu preciso confessar para vocês o meu cansaço e curiosidade. Cansaço porque as coisas teimam em não dar certo. E a minha pouca experiência no assunto e falta de gente pra conversar me atrapalharam bastante a manter o cluster estável. Cheguei a pensar que era melhor reformar um Chevette velho.
Muitos desses erros eu atribuía ao fato de estar rodando tudo num arm64 (a arquitetura do rasp). E de fato alguns problemas advinham daí (já tentou fazer um deploy de Kafka num arm64?). Já outros eram problemas de configuração. Como eu fiz com o Longhorn, exigindo três réplicas, mas mantendo apenas um servidor operando. Com a chegada do meu filho e novos desafios no trabalho, o projeto foi ficando de lado. Até que…
Eu vi um vídeo de um camarada afirmando que conseguiu montar um amd64 com menos de trezentos reais. E aquilo me deixou encabulado. “Será que é verdade?”. Esperei o 13º e assim comprei o meu KIT XEON no AliExpress. No final acabei gastando perto de mil reais. Mas isso porque eu fiz alguns “fru-frus” na máquina. Pra você ter ideia, a peça mais cara é o gabinete!
O computador:
- Placa mãe Mogul (o que definiu o “tema” do case);
- Processador Intel Xeon E5-2680 @ 2.4GHz;
- Placa de Video GeForce GT 610;
- Memória DIMM 16GB (2 pentes) 2133;
- Disco 1 Kingston 200Gb e Disco 2 100 Gb Crucial (ambos SSD);
- O resto é firula.

Você pode pensar que é um “pouco demais” e talvez eu concorde com você. Mas foi o primeiro computador que eu montei do zero. E por si só a experiência foi extremamente divertida. Outro ponto é que eu não tenho um “notebook velho” para transformar em servidor. E eu estava determinado a tirar os “problemas com o arm64” do caminho (como o armazenamento de dados em ssd por exemplo).
Pontos de atenção!
Tudo muito divertido, mas esse ambiente misto carrega um preço. Todo deploy que você fizer precisa considerar a arquitetura do processador em que vai rodar. Ou seja: seus deployments precisam ter um affinity baseado na arquitetura do node. Ou você pode optar por hubs que sabem servir a imagem certa para a arquitetura correta. Leve isso em consideração quando for construir suas próprias imagens.
Para maximizar o esforço aprendizado, instalei em todas as máquinas o Ubuntu Server. Sabe o que isso significa? Zero ambiente gráfico. Tudo é feito via terminal. Isso faz com que tarefas simples como configurar um wifi exijam um esforço extra. As dicas que eu vou discorrer a seguir servem para qualquer sistema baseado em Ubuntu (server ou desktop). Ou seja, tudo bem você usar o Ubuntu Desktop. Mas pelo menos dê uma chance para o VIM. Aqui te dou as dicas básicas para salvar e sair do VIM.
Rede
Eu tentei economizar cabos, comprando um switch PoE. Funcionou muito bem por um ano. Depois algumas portas pararam de funcionar: tanto a energia quanto o tráfego de algumas portas. Por isso, fui forçado a alterar levemente a infraestrutura da rede, comprando um switch menor apenas para o cluster. O que foi uma ideia acertada. Minha infra está assim:
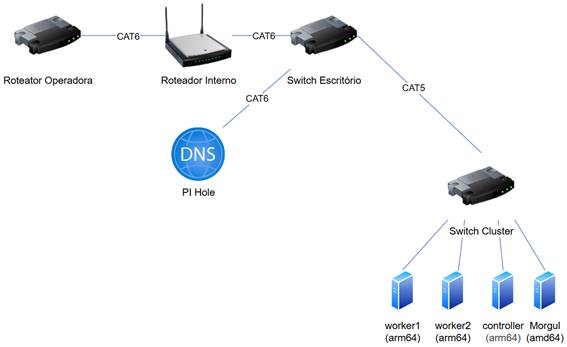
Todos os dispositivos dispões de wifi. No entanto, eu optei por não utilizar o wifi para essas conexões para deixar o roteador mais “leve”. Mas não apenas isso: via cabo a comunicação entre os nodes seria mais rápida. Seria interessante criar uma rede exclusiva para o cluster. O que otimizaria o tráfego ainda mais e não misturaria o “home lab” com a vida cotidiana da casa. Mas daí eu teria que possuir um switch gerenciável. E a grana tá curta pra isso.
Todos os arm64 estão atuando como Workers, embora um deles tenha como nome “controller”. Isso se sucedeu porque, de início, eu gostaria de já criar o cluster com alta disponibilidade (HA). Mas depois de tudo ajustado, desisti. Um problema de cada vez, não é? Também é importante salientar que o Morgul – que vai atuar de fato como controller – também poderá atuar como worker.
E por fim, o último ponto digno de atenção dessa estrutura é que eu tenho um “Orange PI” atuando como DNS da minha rede. Instalei o Pi Hole como bloqueador de informações indesejadas (e sim, sumiram muitos adsense das páginas). Mas a principal motivação era ter ele como DNS primário da casa. Assim endereços como postgres.local.dev ou minha-api.local.dev estarão acessíveis por todo e qualquer dispositivo conectado na minha rede interna. Isso não te dá vontade de criar uma infra de cloud dentro de casa?
Preparativos
Para instalar o sistema operacional – tanto dos raspiberry quanto do ubuntu – eu recomendo que você siga os manuais de cada plataforma. É realmente tão simples quando preparar um SO para bootar de um pen-drive. Por isso vou pular essa parte.
Com o sistema operacional instalado, você precisa configurar o cgroup corretamente para que o Kubernetes seja capaz de gerenciar os recursos disponíveis para cada pod.
Mas o que é o cgroup?
Explicando da maneira mais simples possível: é ele quem diz ao kubernetes quanto está disponível de cada recurso no computador. Memória, CPU, disco são informados pelo cgroup. Agora o que acontece se você tiver swap de memória ativado? O Kubernetes nunca saberá ao certo quando de memória efetivamente está disponível na infraestrutura. Nem disco! Nesse caso, você pode ter pods que demoram (ou nunca serão) derrubados. É por isso que a primeira coisa a se fazer é desativar o swap.
sudo swapoff -aEsse comando desativa o swap no seu computador. Você também pode – e talvez deva – checar o arquivo /etc/fstab para ver se o swap está configurado. Se estiver, deixe todos os valores como zero.
Para verificar se o swap foi realmente desligado, rode o comando abaixo. Se estiver, a saída dele será em branco:
swapon --showQual a versão do cgroup?
Outro ponto importante: Se você instalar o Ubuntu 24, muito provavelmente a única alteração que você deverá fazer é desligar o swap. Mas se instalar outra versão de sistema operacional, você vai ter que verificar se o cgroup está na versão 2 (a versão do SO do rasp é baseada em Debian, então espero que as coisas lá sejam semelhantes).
Para saber a versão do seu cgroup, rode o comando:
ls /sys/fs/cgroupSe você vir arquivos como cgroup.controllers, você está rodando a versão mais recente do cgroup.
Agora é hora de verificar o quais módulos estão ativos no cgroup:
cat /sys/fs/cgroup/cgroup.controllersA saída desse comando vai apresentar todas informações que estão disponíveis via cgroup. Garanta que cpuset cpu io memory pids aparecem como resultado do comando. Se outros aparecerem, não entre na “nóia” de desativá-los. Serão necessários para outros fins.
Se a saída não for parecida com a que demonstrei, provavelmente você precisará ativar os controladores.
No amd64:
Abra o arquivo /etc/default/grub e adicione (ou edite) a linha abaixo:
GRUB_CMDLINE_LINUX="systemd.unified_cgroup_hierarchy=1 cgroup_enable=memory"No arm64:
Abra o arquivo /boot/firmware/cmdline.txt e adicione, ao final da linha:
group_enable=cpuset cgroup_enable=memory cgroup_memory=1NÃO CRIE UMA LINHA NOVA! Todo o conteúdo deve estar na mesma linha!
Banco de dados
Por padrão, o k3s possui um banco que ele utiliza para persistir as informações do seu cluster. Mas para o tamanho da “nossa brincadeira”, eu achei melhor utilizar uma instância de postgres. Idealmente esse banco de dados estaria em uma máquina dedicada, fora do cluster k8s que estamos montando. Mas somos pobres.
Para esse e outros recursos, eu optei por utilizar o próprio docker compose para fazer a orquestrações dos contêineres. Assim eu tenho um postgres que utilizo para as aplicações que tenho rodando (ou estou desenvolvendo) e também para o cluster.
Para as aplicações eu utilizo o DNS que criei para o meu banco. Mas para o cluster, estou informando o endereço de loopback mesmo. Assim evitamos alguns roundtrips desnecessários (e não poluo a minha rede com tráfego desnecessário).
Instalando o k3s
Essa é a parte mais fácil!
No Morgul, execute:
curl -sfL https://get.k3s.io | sh -s - --write-kubeconfig-mode 644 --bind-address <ip-do-controller> --disable-cloud-controller --disable local-storage --datastore-endpoint='postgres://USERNAME:PASSWORD@HOST:5432/k3s?sslmode=disable'Você vai precisar substituir o USERNAME, PASSWORD e HOST pelas configurações do seu banco. Garanta, também, que existe um banco com o nome k3s. Não é preciso criar as tabelas. O próprio k3s faz isso. Mas o banco, você vai precisar criar.
Se quiser usar outro nome para o banco de dados, base mudar a linha de comando que instala o k3s. Eu gosto assim porque fica claro o que ele faz.
No meu caso eu “esqueci” de adicionar esse parâmetro no momento da instalação do k3s. Se esse for o seu caso, altere as configurações do k3s.
sudo systemctl stop k3s.service
sudo vim /etc/systemd/system/k3s.serviceEsses comandos irão parar o serviço do k3s e abrir o arquivo que o configura. Uma vez com o arquivo aberto, procure pela linha que inicia com ExecStart e adicione:
ExecStart=/usr/local/bin/k3s server \
--datastore-endpoint='postgres://USERNAME:PASSWORD@HOST:5432/k3s?sslmode=disable'Mantenha as outras configurações como estão. Apenas adicione essa parte que diz respeito ao banco. Feito isso, salve o arquivo e execute:
sudo systemctl daemon-reload
sudo systemctl start k3s.serviceQuando o prompt estiver disponível novamente, veja o status do serviço com sudo systemctl status k3s.service. Deve mostrar algo como:
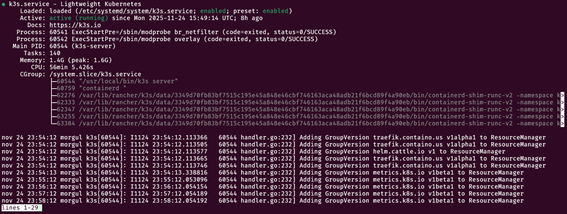
Repare que na terceira linha, na cor verde, temos o status “active (running)”. Nesse caso deu tudo certo. Se algum erro estiver acontecendo durante a inicialização, as linhas de log irão retornar o que pode estar acontecendo.
Chegou a hora de configurar os Workers. Mas isso fica para o próximo artigo.
Se ficou com dúvidas, ou se engasgou em partes desse passo-a-passo, me avise! Vai ser um prazer te ajudar (ou tentar).
One thought on “Criando um cluster kubernetes com raspiberry pi e Kit XEON”