
No artigo anterior nós aprendemos a teoria a respeito de volumes no kubernetes. Chegou a hora de colocarmos a mão na massa, instalando o longhorn no seu cluster k3s.
O que é o Longhorn?
No artigo anterior nós falamos sobre CSI – Container Storage Interface, e como aplicações que implementam o CSI podem ajudar o kubernetes a gerenciar os volumes.
Pois bem, o Longhorn é uma dessas aplicações. Seu uso é mais voltado para ambientes on-prem, já que sua principal tarefa é transformar discos locais em “Discos Virtuais”, disponibilizando parcelas do seu disco para as aplicações. E melhor ainda: O Longhorn possui a capacidade de replicar esse conteúdo, diminuindo a possibilidade de você perder os dados por que um node do seu cluster morreu.
E tudo isso com uma interface simples de usar e configurar os seus discos.
Antes de instalar o longhorn, você precisa configurar os seus discos!
Configurando disco para usar como volume no Longhorn
Por padrão, o Longhorn irá montar um volume dentro de uma pasta. Apesar de isso ser possível, eu prefiro recomendar que você compre um SSD, nem que seja pequeno, pra usar exclusivamente pra o cluster. Eu sinto que o meu environment fica mais seguro dessa maneira.
Uma questão importante: Eu tentei ligar o meu SSD no meu Raspiberry PI. E não deu lá muito certo. Não tive tempo de descobrir as razões, mas estou jogando na conta da gestão de energia. Por mais que tenham baixo consumo, as configurações do Raspiberry também são e como ele não possui fonte de alimentação como a dos computadores comuns, tudo que está plugado nele concorre com os míseros 5v 3a disponíveis no USB-C.
Por isso o passo-à-passo que se segue, considera que estou formatando o disco na máquina Morgul. Mas você pode arriscar adicionar um SSD por máquina e me relatar qual mágica você fez.
O primeiro passo é garantir que temos todas as ferramentas.
Instalando os pacotes de gestão de disco
Vamos instalar alguns programas que nos ajudarão a gerenciar os discos. São eles:
ansible all -b -m apt -a "name=nfs-common state=present" -i ./inventory
ansible all -b -m apt -a "name=open-iscsi state=present" -i ./inventory
ansible all -b -m apt -a "name=util-linux state=present" -i ./inventoryPerceba que eu utilizei o ansible para instalar em todas as máquinas. Mas você pode optar por rodar o apt install manualmente no seu computador. O módulo apt que utilizamos acima, faz exatamente isso:
sudo apt install nfs-common open-iscsi util-linuxIdentificando os discos
Você precisa descobrir como Linux está identificando os discos. Isso é importante porque é justamente esse “nome” que você vai utilizar para lidar com esse storage. Para isso, utilize o comando lsblk. E se você é iniciante em linux, aqui vai uma dica:
- ls: a maior parte dos comando do terminal que começam com `ls`são de listagem.
- blk: abreviação para block. No nosso caso, block storage, que você pode entender como dispositivos que armazenam em blocos (igual todo HD faz desde sempre).
- –help ou -h: na maior parte das vezes, chamar qualquer linha de comando com esses parâmetros te fornecerá ajuda sobre como utilizar o CLI.
Para rodar com o ansible, você pode executar o comando:
ansible all -b -m shell -a "lsblk -f" -i ./inventoryOu pode executar manualmente com lsblk -f. Você verá algo parecido com:
morgul | CHANGED | rc=0 >>
NAME FSTYPE FSVER LABEL UUID FSAVAIL FSUSE% MOUNTPOINTS
sda ext4 1.0 e9c01c2b-8330-46bc-aeed-a8fa5f696e2c 102,5G 1% /storage01
sdb
├─sdb1 vfat FAT32 ECC8-3EC7 1G 1% /boot/efi
├─sdb2 ext4 1.0 6d025d9f-de5f-44c9-8663-765508eabd96 1,6G 10% /boot
└─sdb3 LVM2_member LVM2 001 iOeWjJ-Ibs9-pVS7-2ZU7-kw8G-mLfr-hRWyun
└─ubuntu--vg-ubuntu--lv ext4 1.0 68d74f52-f044-434e-b4fb-123e6b2b5bf7 55,6G 38% /
sdc ext4 1.0 7c22bd01-7f18-49ac-bad2-3eaf025b60feSe você executar o comando para todos os nós verá 3 saídas muito semelhantes ao que vemos acima.
O comando lsblk -f lista os discos e partições disponíveis pelo sistema operacional. Cada sd[a..z] é um disco e cada sd[a..z][1..9] é uma partição dentro do disco (sda1 é uma partição dentro do disco sda). Esses nomes são “user friendly” e não devem ser utilizados para endereçamento; a adição de novos discos pode alterar essa nomenclatura, desfazendo o link feito. Para endereçamento, prefira utilizar o uuid. No nosso caso estamos com 3 discos. O sdb é o disco onde está rodando o sistema operacional. Você pode perceber isso olhando que o /boot é uma das partições desse disco. Como eu já estou rodando o k3s no morgul, ao listar os discos eu vejo o sdc. Esse disco “virtual” foi criado pelo Longhorn (já instalado) e todas as PV’s residem lá. De forma que o sda é a representação física do disco sobressalente que instalei para o meu cluster.
No meu inventory do ansible, possuo uma varíavel onde armazeno, nesse primeiro momento, o nome do disco para manipulação. É interessante utilizar o nome nesse momento, já que ao reconstruir as partições, o UUID será perdido. Então não adicione discos por enquanto.
Para cada nó que possua uma disco, repita a essa configuração.
Agora que sabemos qual disco vamos disponibilizar, vamos reescrever a tabela de partições dele. É como se você estivesse fazendo uma “formatação rápida” do disco.
ansible morgul -b -m shell -a “wipefs -a /dev/{{ var_disk }}” -i ./inventory
ansible morgul -b -m filesystem -a “fstype=ext4 dev=dev/{{ var_disk }}” -i ./inventoryA primeira linha executa o programa wipe, que é o responsável por limpar a tabela de partições do disco. Já o segundo comando define um filesystem para o disco selecionado.
Com esses comandos o seu disco está formatado e com um sistema de arquivos definido. É hora de montá-lo. E para evitar problemas, caso você adicione novos discos, ao invés de utilizar o nome (sda, por exemplo), vamos utilizar o uuid do disco. Para identificar, rode:
ansible morgul -b -m shell -a "blkid -s UUID -o value /dev/{{ var_disk }}" -i ./inventory
morgul | CHANGED | rc=0 >>
e9c01c2b-8330-46bc-aeed-a8fa5f696e2cA saída do comando é o UUID que representa o disco. Atualize, novamente, o inventário com o uuid na variável `var_uuid` e rode o comando:
ansible morgul -m ansible.posix.mount -a "path=/storage01 src=UUID={{ var_uuid }} fstype=ext4 state=mounted" -b -i ./inventoryTodas as vezes que o computador for iniciado, ele automaticamente montará a unidade em sda (ou melhor, em “e9c01c2b-8330-46bc-aeed-a8fa5f696e2c”) no caminho “/storage01”. E durante a instalação do Longhorn você vai descobrir porque esse nome é tão importante.
Como instalar o Longhorn?
Você pode escolher entre escrever vários arquivos .yaml, definindo os recursos manualmente. Ou você pode utilizar o helm para instalar. Vai por mim, helm é a melhor opção. E você não é “menos” por usar ferramentas que facilitem a sua vida. Assim sendo, a primeira coisa é adicionar o repositório do Longhorn ao seu Helm.
helm repo add longhorn https://charts.longhorn.io
helm repo updateAgora o Longhorn está disponível para ser instalado localmente.
helm install longhorn longhorn/longhorn \
--namespace longhorn-system \
--create-namespaceO comando acima instala o Longhorn, mas você vai ter que fazer uma série de modificações depois. Você pode continuar utilizando a linha de comando para definir/alterar comportamentos do helm. Ou pode utilizar um arquivo values.yaml para escrever de forma mais declarativa.
ingress:
enabled: true
ingressClassName: traefik
host: longhorn.home.arpa
path: /
pathType: Prefix
tls: true
tlsSecret: wildcard-home-arpa
annotations:
traefik.ingress.kubernetes.io/router.entrypoints: websecure
traefik.ingress.kubernetes.io/router.tls: "true"
persistence:
defaultClass: false
defaultSettings:
defaultDataPath: "/storage01"
settings:
service:
ui:
type: "ClusterIP"Para rodar o helm com essa configurações, execute:
helm install longhorn longhorn/longhorn \
--namespace longhorn-system \
--create-namespace \
-f values.yamlExplicando os parâmetros:
--namespace: Define sob qual namespace o helm será instalado--create-namespace: Garante o que o namespace será criado, caso não exista;--f: define o arquivo contendo os valores do helm. Outra opção seria definir os valores utilizando o parâmetro--set.defaultSettings.defaultDataPath: Especifica o path padrão onde o Longhorn irá montar seus discos;servisse.ui.type: Diz qual tipo de service será contruído para a UI. Você pode optar por LoadBalancer, expondo o service para o mundo, ou ClusterIP, se for utilizar port forward ou ingress (nosso caso).ingress: Aqui eu consigo definir o ingress para acessar a UI do Longhorn.
Para maiores detalhes sobre as configurações disponíveis, acesse a página do longhor no artifact hub.
Caso o ingress não esteja funcionando, pode ser porque você não tem certificados disponíveis no seu cluster. Nesse caso, altere
websecureporwebe remova as linhastls: trueetlsSecret: wildcard-home-arpa. Nós vamos criar esses certificados em outro momento.
Para ver se todos os pods estão disponíveis, digite:
kubectl -n longhorn-system get podsVocê deve ter um retorno parecido com esse:
➜ kubectl get pods -n longhorn-system
NAME READY STATUS RESTARTS AGE
instance-manager-a492f16963e40116ed3c78c3fe7baf3a 1/1 Running 0 15d
longhorn-manager-6bmnn 2/2 Running 5 (15d ago) 24d
longhorn-csi-plugin-jvr59 3/3 Running 6 (15d ago) 24d
csi-provisioner-5bc974d757-764lh 1/1 Running 35 (9d ago) 24d
csi-snapshotter-f476574cd-g6fjk 1/1 Running 9 (15d ago) 24d
engine-image-ei-3154f3aa-d2p48 1/1 Running 2 (15d ago) 24d
csi-attacher-7b76b6f544-s26tz 1/1 Running 8 (15d ago) 24d
longhorn-csi-plugin-9wzp6 3/3 Running 3 (15d ago) 21d
engine-image-ei-3154f3aa-dzxdz 1/1 Running 1 (15d ago) 21d
instance-manager-200d71ef3d1c9ee5a1df6f9fe2418ea6 1/1 Running 0 15d
longhorn-manager-z94dt 2/2 Running 2 (15d ago) 21d
engine-image-ei-3154f3aa-fs8b9 1/1 Running 2 (15d ago) 24d
csi-snapshotter-f476574cd-2zxdm 1/1 Running 3 (15d ago) 24d
csi-resizer-78fb4875d7-9hxzh 1/1 Running 6 (15d ago) 24d
longhorn-csi-plugin-vnrhp 3/3 Running 6 (15d ago) 24d
instance-manager-90b7392cc3367760c0a1cb5393280750 1/1 Running 0 15d
longhorn-ui-55b69f57d4-ggrcp 1/1 Running 4 (15d ago) 24d
longhorn-manager-l7s4x 2/2 Running 4 (15d ago) 24d
csi-attacher-7b76b6f544-csmtl 1/1 Running 7 (2d3h ago) 24d
engine-image-ei-3154f3aa-jrl57 1/1 Running 10 (2d3h ago) 24d
csi-attacher-7b76b6f544-rbljf 1/1 Running 12 (2d3h ago) 24d
csi-provisioner-5bc974d757-cp4br 1/1 Running 16 (2d3h ago) 24d
csi-snapshotter-f476574cd-st8rc 1/1 Running 14 (2d3h ago) 24d
csi-resizer-78fb4875d7-cxwfv 1/1 Running 13 (2d3h ago) 24d
longhorn-csi-plugin-8zqbt 3/3 Running 32 (2d3h ago) 24d
csi-resizer-78fb4875d7-wsg27 1/1 Running 10 (2d3h ago) 24d
longhorn-driver-deployer-6c7d966776-h77ps 1/1 Running 9 (2d3h ago) 24d
longhorn-ui-55b69f57d4-nssg5 1/1 Running 17 (2d3h ago) 24d
instance-manager-fff476f40cf27e153d73d998d36bc6aa 1/1 Running 0 2d3h
longhorn-manager-9v4dq 2/2 Running 20 (2d3h ago) 24d
csi-provisioner-5bc974d757-2cn8q 1/1 Running 27 (2d3h ago) 24dTodos os pods estão ready e running. Exatamente como esperávamos. Na minha listagem, ignore os restarts. Eu tive alguns problemas de rede e com os pods no período (chuvas e aquecimento global) que podem ter causado o restart.
Acessando a UI do Longhorn
Pode ser interessante garantir que o seu ingress está ok. Para isso, digite no terminal kubectl get ingress -n longhorn-system. A saída deve ser parecida com:
➜ kubectl get ingress -n longhorn-system
NAME CLASS HOSTS ADDRESS PORTS AGE
longhorn-ingress traefik longhorn.home.arpa 192.168.1.145,192.168.1.146,192.168.1.147,192.168.1.212 80, 443 33sSe não houver nenhuma lista de IPs, o seu ingress não está vinculado corretamente.
Caso queira ver a definição do ingress feito pelo helm, digite: kubectl get ingress -n longhorn-system -o yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
annotations:
argocd.argoproj.io/tracking-id: longhorn:networking.k8s.io/Ingress:longhorn-system/longhorn-ingress
field.cattle.io/publicEndpoints: '[{"addresses":["192.168.1.145","192.168.1.146","192.168.1.147","192.168.1.212"],"port":443,"protocol":"HTTPS","serviceName":"longhorn-system:longhorn-frontend","ingressName":"longhorn-system:longhorn-ingress","hostname":"longhorn.home.arpa","path":"/","allNodes":false}]'
traefik.ingress.kubernetes.io/router.entrypoints: websecure
traefik.ingress.kubernetes.io/router.tls: "true"
labels:
app: longhorn-ingress
app.kubernetes.io/instance: longhorn
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: longhorn
app.kubernetes.io/version: v1.10.1
helm.sh/chart: longhorn-1.10.1
name: longhorn-ingress
namespace: longhorn-system
spec:
ingressClassName: traefik
rules:
- host: longhorn.home.arpa
http:
paths:
- backend:
service:
name: longhorn-frontend
port:
number: 80
path: /
pathType: Prefix
tls:
- hosts:
- longhorn.home.arpa
secretName: wildcard-home-arpaAo acessar https://longhorn.home.arpa, você deverá ver a carinha do Longhorn.
Desativando nodes desnecessários
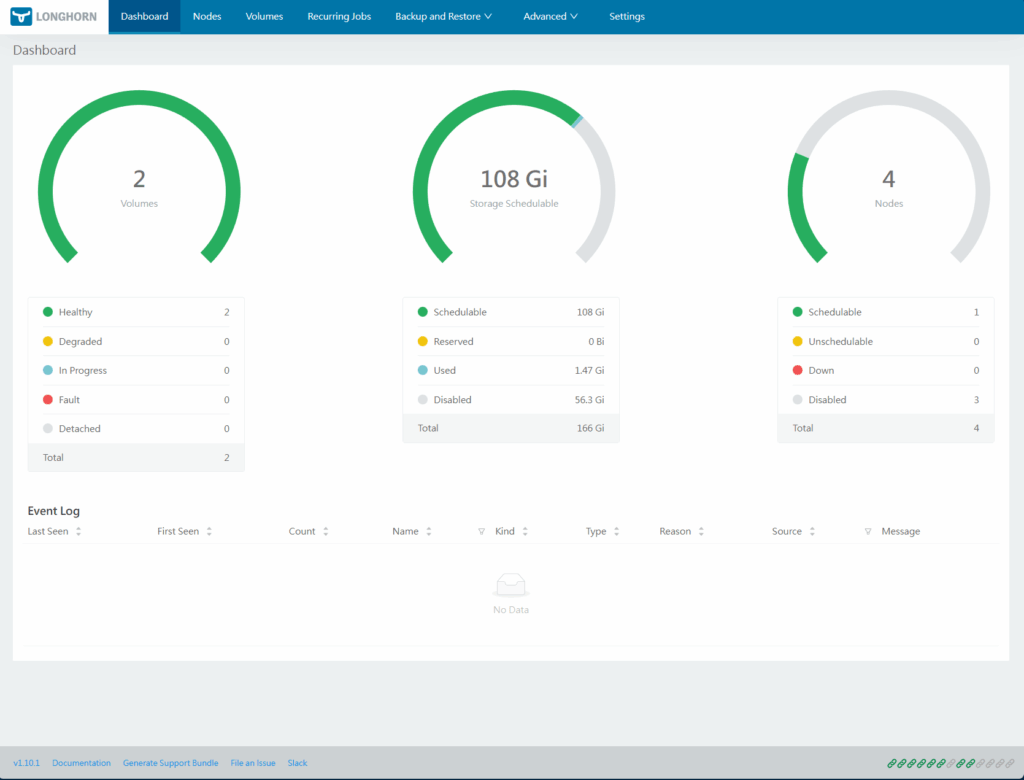
Como eu disse antes, eu não estou utilizando o poder de replicação do Longhorn. Por isso, posso – e talvez até deva – configurar o longhorn para que não faça dos outros pods agendáveis. Assim discos não serão criados neles. Para isso, clique em “Nodes”.
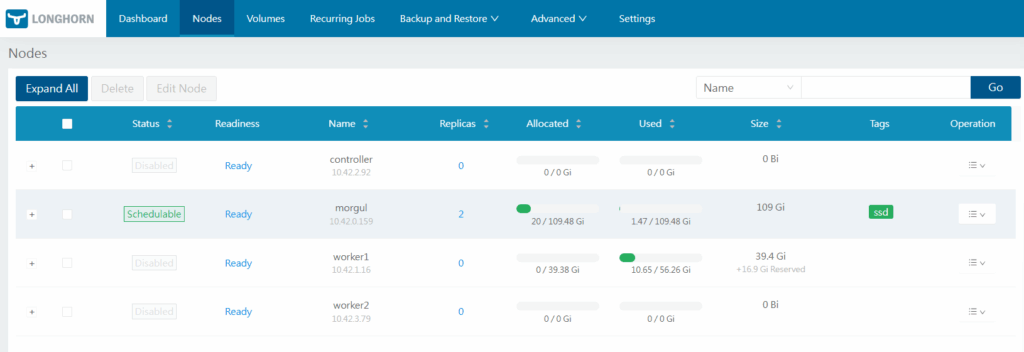
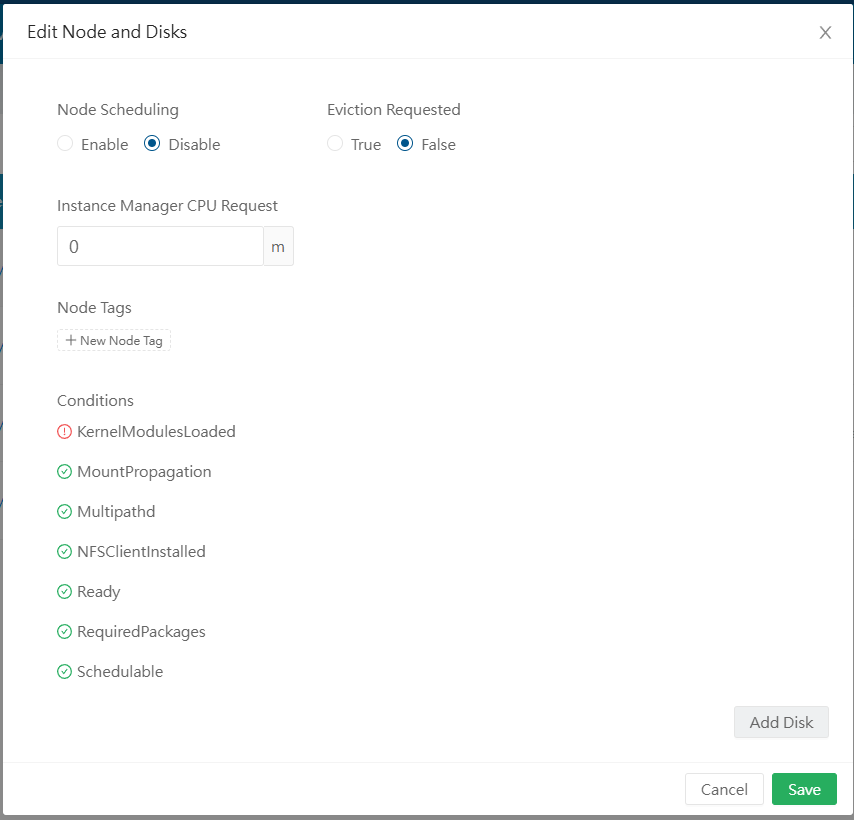
Na coluna “Operation”, você consegue ver as opções possíveis com o node. Clique em “Edit node and Disk”. Um modal com os discos disponíveis no node será aberto. Procure por “Node Scheduling” e marque como “Disable”. Na seção dos discos, mais para baixo no modal, também marque a opção “Scheduling” como “Disable”. Clique no botão “Save” no canto inferior direito (role o mouse, se necessário). Se tentar entrar novamente no node, verá algo como à seguir:
Criando um StorageClass para o SSD
Por padrão o Longhorn cria um storage class que mapeia os discos para o HD do sistema operacional. Dessa forma, caso você queira ativar os demais nodes sem adicionar um HD neles, o longhorn irá criar a pasta no mesmo disco /boot. Que pode ser um pendrive ou um microSD!
Para evitar dores de cabeça, eu costumo criar um storageClass personalizado, que sempre irá olhar para os SSD que estiverem disponíveis no meu cluster. Assim todas as minhas PVCs vão utilizar esse storageClass, apontando para o SSD. Antes, vamos configurar alguns detalhes no disco do morgul.
Siga o mesmo caminho para desabilitar os nodes, mas agora escolha o morgul. Você verá algo semelhante a isso:
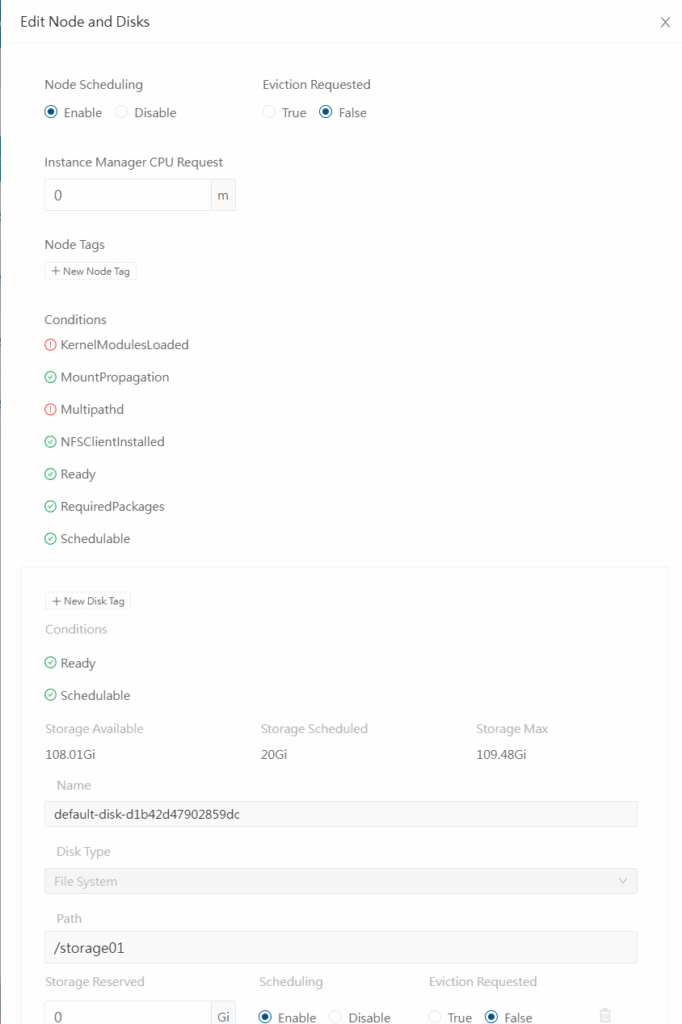
Como você pode ver, é possível fazer várias configurações no node e no disco. Mas por hora vamos nos concentrar nas tags. Crie tags ssd para o node e para o disco, ficando dessa maneira:
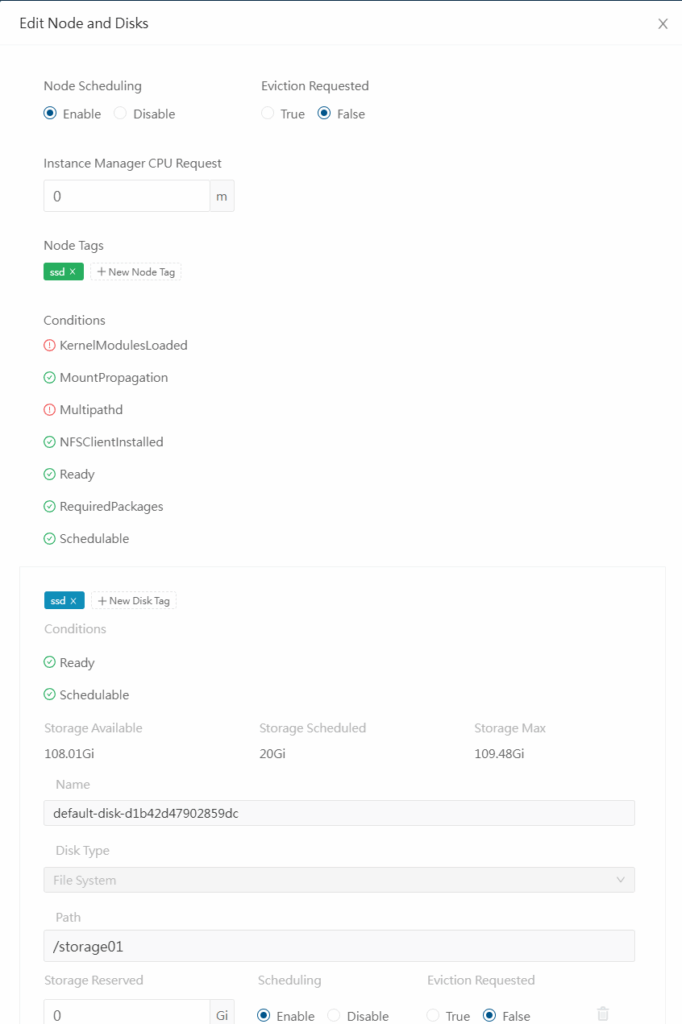
Clique no botão “Save” no canto inferior direito e vamos escrever a nossa storageClass personalizada.
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: longhorn-fast
provisioner: driver.longhorn.io
allowVolumeExpansion: true
reclaimPolicy: "Delete"
volumeBindingMode: Immediate
parameters:
numberOfReplicas: "1"
staleReplicaTimeout: "30"
fsType: "ext4"
diskSelector: "ssd"
nodeSelector: "ssd"O manifesto acima cria uma storageClass que utiliza o Longhorn CSI. Perceba as configurações:
parameters.numberOfReplicas: Como estamos trabalhando com apenas um disco, não faz sentido ter mais de uma réplica. Altere esse número caso tenha mais de um SSD disponível (ideal seriam sempre 3 réplicas);parameters.fsType: o filesystem do disco que estamos disponibilizando;diskSelectorenodeSelector: com base nas tags que adicionamos antes, esses selectores escolhem em qual node serão criados e mantidos os volumes.
Rode o comando kubectl apply -f longhorn-fast.yaml e prontinho! Seu cluster está pronto para utilizar Longhorn e “clamar” por espaço em disco.
Você deve ter percebido que utilizamos bastante arquivos yaml e helm para adicionar programas ao nosso cluster. Não seria divertido se houvesse um programa em que, toda vez que eu altero um desses manifestos, ele o aplique no kubernetes automaticamente? Acho que você já sabe o que vem por aí. Uma dica: Se eu trocar todas as peças de maneira de um barco ele continua sendo o mesmo barco?
Vejo vocês no próximo post!